In this blog post I'll describe some work I did a while ago in a consulting project together with Bengler. The work was a consultancy project for the national museum that was started in 2015 and the final result, VY, was made public in May last year. There were however some more experiments we tried during this project that I thought might be interesting to share.
I was contacted by Bengler in 2014 regarding a potential project for Nasjonalmuseet. Nasjonalmuseet is Norways national gallery containing more than 30000 works of art, the most famous of them probably being Edvard Munchs' The Scream. The original proposal was to do something involving face recognition, since I'd released the face substitution demo not so long ago, but after some thought we decided to have a look at whether it would be possible to apply Deep Learning to the fine arts collection.
Visualization
One of our first ideas was to try to visualize the collection in some way. Though the museum had webpages showing off parts of their collection, it was hard to get a complete overview of the entire collection as well as the many subjects found in the collection. t-SNE visualizations of deep learning features had worked well for another project of mine, so we decided to give this a try. At this point we had no idea whether this really would work for artworks as well, but as it turns out it did work really well.
In order to ensure that the embeddings became meaningful, we decided to train a deep learning classifier to classify artworks into art styles and motifs respectively. The models did not get super-high accuracy at that task, but that was not the main goal either. We simply wanted the features from the last layer of the trained classifier, which we used as input to a t-SNE model. As can be seen by the resulting t-SNE embedding below, this worked pretty well.

We got smooth transitions from nationalromantic paintings focusing on seas, through fjords, to forests.

And from portraits one can clearly see clustering of women, bearded men, and full person portraits.

Visualizations were most interesting for paintings. Though they work just as well for drawings, it's harder to get a proper overview of the collection of the drawings, due to the reduced contrast of pencil drawings at small resolutions.
For the final public work we decided to try out parametric t-SNE, since we would have to make it possible for the t-SNE map to grow without having to retrain it for every addition to the collection. To our surprise, this seemed to give slightly better and more coherent t-SNE maps than the regular t-SNE method.

The features from our trained classifier can be used for more things than just visualization. We can also figure out what the typical works from a period looks like, by looking at works close to the mean embedding within a specific period. These works clearly show how typical norwegian painting gradually went from mainly nationalromantic landscape themes in mid 1800s, through to social realism at the turn of the century, and eventually abstraction in the fifties.
















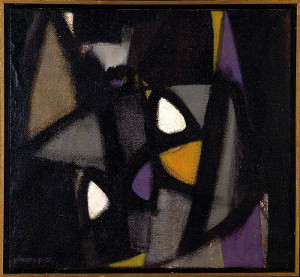



Similarly, we can also investigate if there are any stylistic outliers, by looking at works that are far from the mean embedding within each decade.








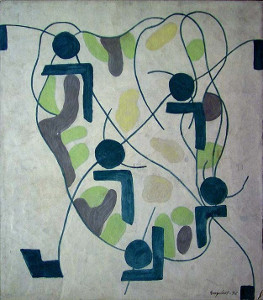



An interesting detail we noted is that outliers often signified trends that became commonplace a few decades later, such as the gradual shift to abstract painting.
Faces in the collection
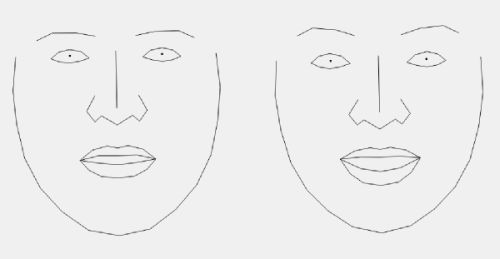
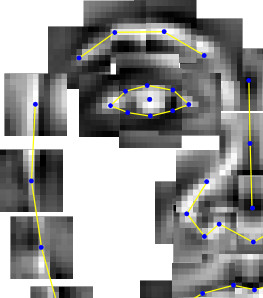
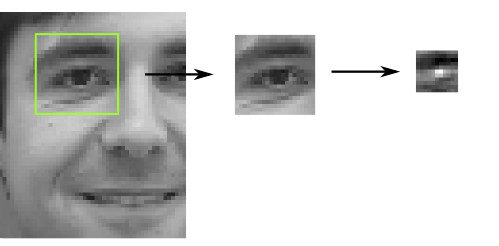
Since the original proposal involved doing something with faces in the collection, we also decided to have a look at applying similar visualization methods there. After detecting most faces in the collection and cropping them out, we tried out using a pretrained face-similarity embedding which we fed into a t-SNE model, but though the resulting embedding seemed to separate between male, bearded faces, and more feminine faces, the t-SNE visualizations didn't make quite as much sense as with the painting embeddings above. We suspected this might have to do with the difference between faces in paintings and photographies, so we even collected a dataset of painted fan-art of celebrities which we finetuned the face-similarity model on, but unfortunately it did not seem to have a significant effect on the quality of the visualization.

A follow-up idea we had was to make some kind of web app to allow visitors to find the faces in the collection most similar to their own, but due to time and budget constraints, we decided to scrap this idea. Fortunately, Google created just that a couple of months later, on a much larger collection of artworks.
Generating paintings
Of course, in 2016, sitting with a dataset of prime nationalromantic art, the temptation to train a Generative Adversarial Network on it was too strong. So naturally, we did just that. To train a DCGAN generating nationalromantic works, we first trained a GAN on a diverse set of styles of paintings from wikimedia, and then finetuned the model to a small augmented dataset of nationalromantic paintings. This is some of the results we got:









While they might not pass for authentic works by Tidemand & Gude, they do look like coherent, though vague nationalromantic paintings
We had no problem training a model (using DCGAN-tensorflow) to produce 256x256 paintings, though we quite often ran into the dreaded mode-collapse problem, which means all output converged to an abstract blob, so we'd have to start from scratch. We of course also tried to produce even larger 512x512 paintings, but this was more than our poor GPU RAM could handle. Efforts to scale up 256x256 images with superresolution also didn't work out well, since the superresolution mainly just sharpened artifacts in the image and added more noise.
Since we finished this project, there has been numerous improvements made to GAN models (one being Nvidia Researchs progressive growing GAN), which leads us to believe there is a huge potential to experiment more with GANs and art.
Conclusion
In finishing, I'd like to give a huge thanks to Bengler and the staff at the national museum, for their belief in the project and the free reins they gave us. Both during and after we worked on this project, we've seen similar projects, such as Googles Arts & Cultures Experiments, this, this and this. We believe there is lots of potential for fruitful collaboration between the fields of art and modern machine learning.
If you're interested in more info about what we did, also take a look at Benglers writeup of the project, as well as this blogpost on our experiments with training a model to classify paintings into iconclass classes.
If you enjoyed this post, you should follow me on twitter!
]]>